什么是 Reactor 模式
反应器设计模式(Reactor pattern)是一种为处理并发服务请求,并将请求提交到一个或者多个服务处理程序的事件设计模式。当客户端请求抵达后,服务处理程序使用多路分配策略,由一个非阻塞的线程来接收所有的请求,然后派发这些请求至相关的工作线程进行处理。
Reactor 模式结构
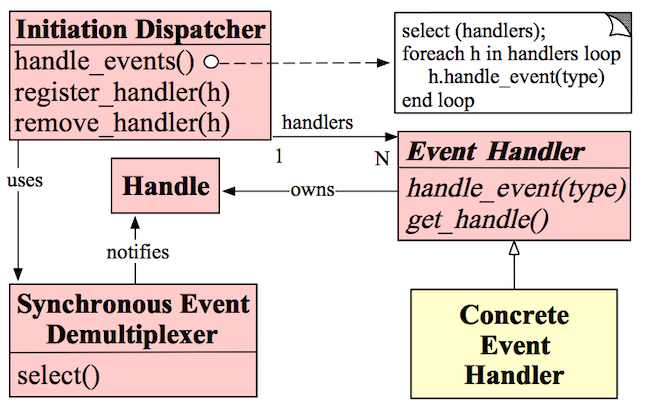
- Handle:句柄,指 Windows 中的句柄,在 Linux 中一般称为文件描述符,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个套接字(Socket)、Timer 等。由于 Reactor 模式一般使用在网络编程中,因而这里一般指 Socket Handle,即一个网络连接(Connection)。这个 Handle 注册到 Synchronous Event Demultiplexer 中,以监听 Handle 中发生的事件,对 Server Socket Handle 可以是 CONNECT 事件,对 Socket Handle 可以是 READ、WRITE、CLOSE 事件等。
- Synchronous Event Demultiplexer:同步事件分离器,本质上是系统调用。比如 Linux 中的 select、poll、epoll。会阻塞等待一系列的 Handle 中的事件到来,如果阻塞等待返回,即表示在返回的 Handle 中可以不阻塞的执行返回的事件。
- Initiation Dispatcher:初始分发器,用于管理 Event Handler,即 Event Handler 的容器,提供注册、移除 Event Handler 的方法;另外,它还作为 Reactor 模式的入口调用 Synchronous Event Demultiplexer 的 select 方法以阻塞等待事件返回,当阻塞等待返回时,根据发生事件的 Handle,Initiation Dispatcher 将其分发给对应的 Event Handler 处理,即回调 Event Handler 中的 handle_event() 方法。
- Event Handler:事件处理器,定义事件处理方法:handle_event(),以供 Initiation Dispatcher 回调使用。当 Handle 上有事件发生时,回调方法便会执行,一种事件处理机制。
- Concrete Event Handler:具体的事件处理器,事件 Event Handler 的接口,实现特定事件处理的业务逻辑。
Reactor 模式处理流程
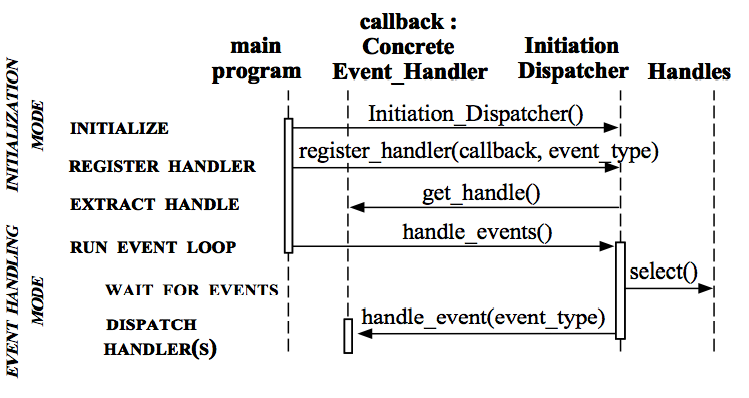
(1)初始化 Initiation Dispatcher,并初始化一个 Handle 到 Event Handler 的映射(Map)。
(2)注册 Event Handler 到 Initiation Dispatcher 上,每个 Event Handler 包含对相应 Handle 的引用,从而建立 Handle 到 Event Handler 的映射(Map)。
(3)当所有的 Event Handler 都注册到 Initiation Dispatcher 上后,Initiation Dispatcher 会调用 handle_events() 方法来启动 Initiation Dispatcher 的事件循环,这时 Initiation Dispatcher 会将每个 Event Handler 关联的 Handle 合并,并使用 Synchronous Event Demultiplexer 调用 select() 方法来阻塞等待 Handle 上事件的发生。
(4)当与某个或某些 Handle 对应的 Event 发生时,Synchronous Event Demultiplexer 便会通知 Initiation Dispatcher。
(5)Initiation Dispatcher 会根据相应的 Handle 触发 Event Handler 的 handle_event() 回调方法。
(6)在 Event Handler 的 handle_events() 方法中还可以向 Initiation Dispatcher 中注册新的 Event Handler。比如对 Acceptor Event Handler 来说,当有新的 Client 连接时,它会产生新的 Event Handler 以处理新的连接,并注册到 Initiation Dispatcher 中。
Reactor 模式实例
在 Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events 中,一直以 Logging Server 来分析 Reactor 模式,这个 Logging Server 的实现完全遵循这里对 Reactor 的描述,因而放在这里以做参考。
Logging Server 中的 Reactor 模式实现分两个部分:Client 连接到 Logging Server 和 Client 向 Logging Server 写 log 。因而对它的描述分成这两个步骤。
Client 连接到 Logging Server
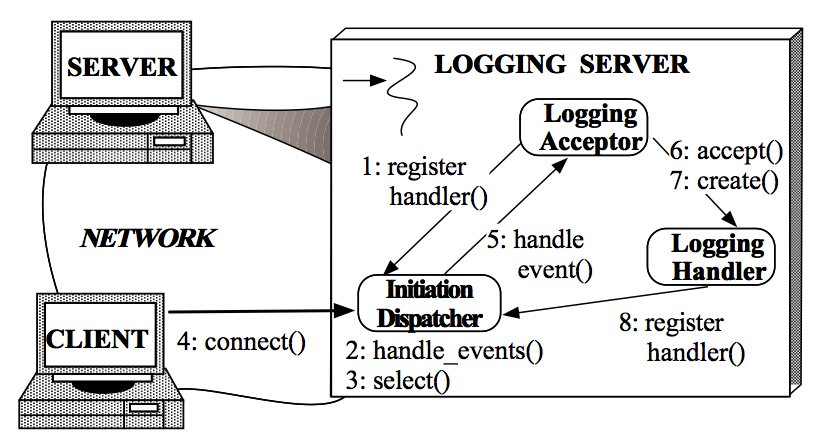
(1)Logging Server 注册 Logging Acceptor 到 Initiation Dispatcher。
(2)Logging Server 调用 Initiation Dispatcher 的 handle_events() 方法启动。
(3)Initiation Dispatcher 内部(Synchronous Event Demultiplexer)调用 select() 方法,阻塞等待 Client 连接。
(4)Client 连接到 Logging Server。
(5)Initiation Disptcher 中的(Synchronous Event Demultiplexer) select() 方法返回,并根据返回找到 Logging Acceptor 并告知其有新的连接到来。
(6)Logging Acceptor 调用 accept() 方法接受这个新连接。
(7)Logging Acceptor 调用 create() 方法创建新的 Logging Handler。
(8)新的 Logging Handler 注册到 Initiation Dispatcher 中(同时也注册到 Synchonous Event Demultiplexer 中),等待 Client 发起写 log 请求。
Client 向 Logging Server 写 log
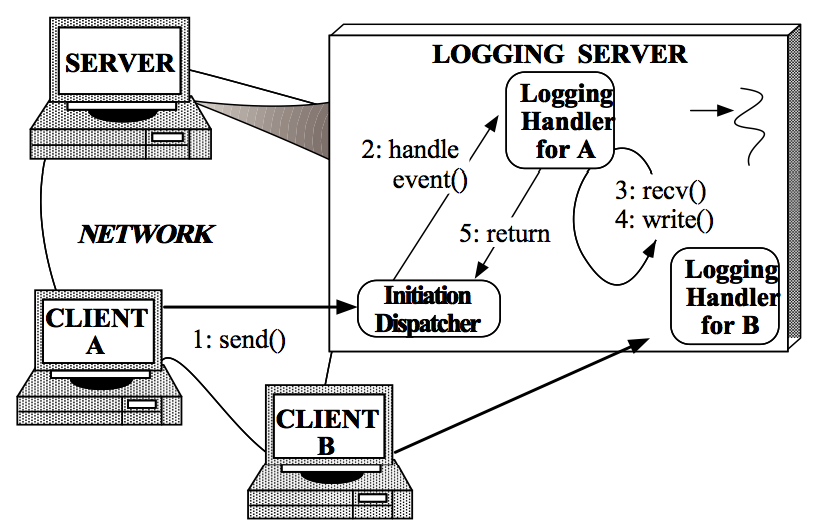
(1)Client 发送 log 到 Logging Server。
(2)Initiation Dispatcher 中的(Synchronous Event Demultiplexer)监测到相应的 Handle 中有事件发生,select() 方法返回,根据返回的 Handle 找到 Logging Handler,并回调 Logging Handler 中的 handle_event() 方法。
(3)Logging Handler 中的 handle_event() 方法中使用 recv() 方法读取 Handle 中的 log 信息。
(4)将接收到的 log 信息使用 write() 方法写入到日志文件、数据库等中。步骤 3 和 4 循环直到当前日志处理完成。
(5)返回到 Initiation Dispatcher 等待下一次日志写请求。
如何使用 Reactor 模式
在网络服务和分布式对象中,对于网络中的某一个请求处理,我们比较关注的内容大致为:读取请求(Read request)、 解码请求(Decode request)、处理服务(Process service)、 编码答复(Encode reply)、 发送答复(Send reply)。但是每一步对系统的开销和效率又不尽相同。
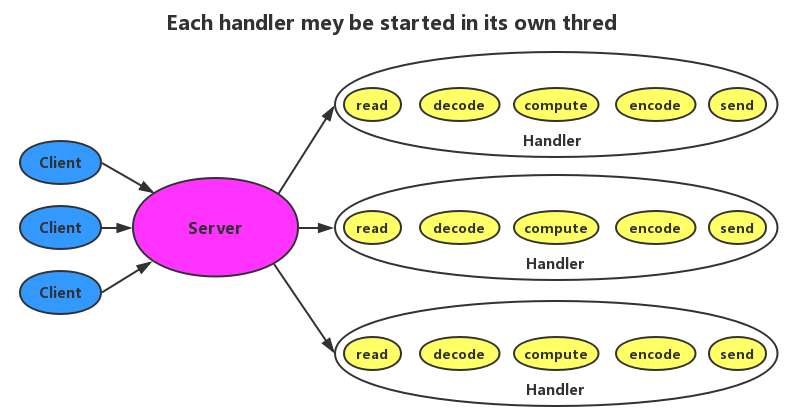
传统服务设计(Classic Service Design)
对于传统的服务设计,每一个到来的请求,系统都会分配一个线程去处理,这样看似合乎情理,但是,当系统请求量瞬间暴增时,会直接把系统拖垮。因为在高并发情况下,系统创建的线程数量是有限的。传统系统设计如下图所示:
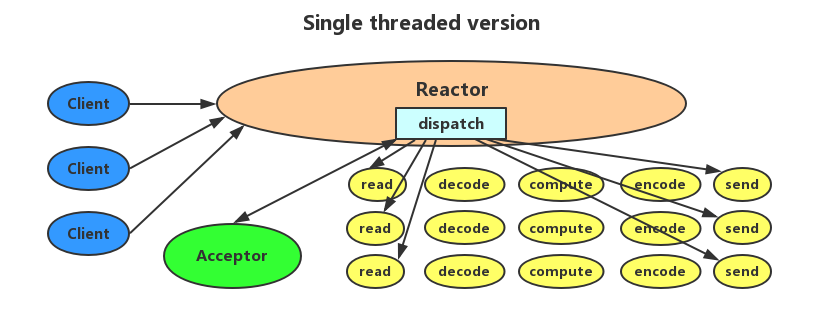
基础 Reactor 设计(Basic Reactor Design)
单线程版的 Reactor 模式如下图所示。对于客户端的所有请求,都有一个专门的线程去进行处理,这个线程无限循环去监听是否有来自客户端的请求到来,一旦收到客户端的请求,就将其分发给相应的处理器进行处理。
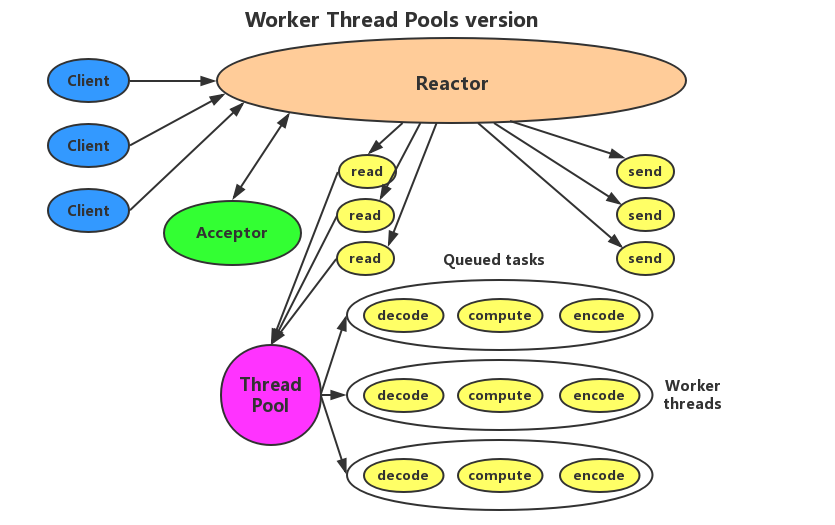
工作线程池 Reactor 设计(Worker Thread Pools for Reactor)
考虑到工作线程的复用,将工作线程设计为线程池。将处理器的执行放入线程池,多线程进行业务处理。但 Reactor 仍为单个线程。工作线程使用线程池实现如下图所示。
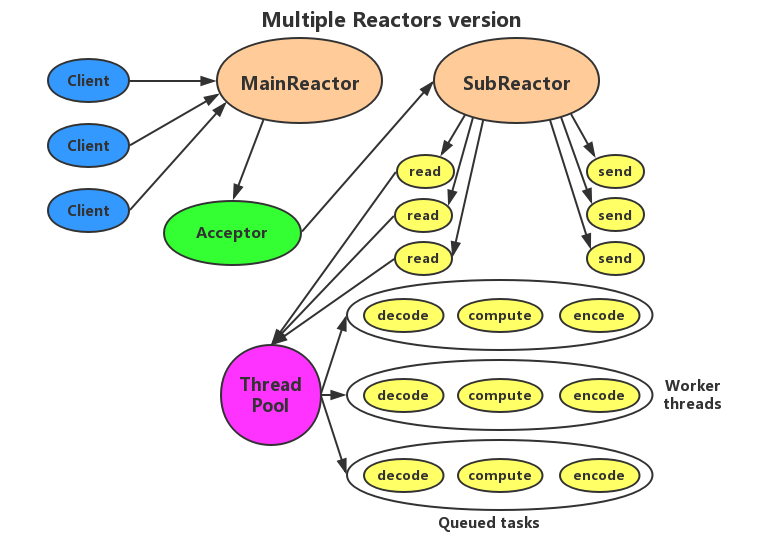
多 Reactor 设计(Multiple Reactor Design)
对于多个 CPU 的机器,为充分利用系统资源,将 Reactor 拆分为两部分。MainReactor 负责监听连接,accept 连接给 SubReactor 处理,为什么要单独分一个 Reactor 来处理监听呢?因为像 TCP 这样需要经过3次握手才能建立的连接,建立连接的过程也是要耗时间和资源的,单独分一个 Reactor 来处理,可以提高性能。实现如下图所示。
总结
优点
(1)响应快,不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的。
(2)编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销。
(3)可扩展性,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源。
(4)可复用性,Reactor 框架本身与具体事件处理逻辑无关,具有很高的复用性。
缺点
(1)相比传统的简单模型,Reactor 增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
(2)Reactor 模式需要底层的 Synchronous Event Demultiplexer 支持,比如 Java 中的 Selector 支持,操作系统的 select 系统调用支持,如果要自己实现 Synchronous Event Demultiplexer 可能不会有那么高效。
(3) Reactor 模式在 I/O 读写数据时还是在同一个线程中实现的,即使使用多 个Reactor 机制的情况下,那些共享一个 Reactor 的 Handle 如果出现一个长时间的数据读写,会影响这个 Reactor 中其他 Handle 的相应时间,比如在大文件传输时,I/O 操作就会影响其他 Client 的相应时间,因而对这种操作,使用传统的 Thread-Per-Connection 或许是一个更好的选择,或则此时使用 Proactor 模式。
参考
- Reactor模式:https://www.jianshu.com/p/eef7ebe28673
- 高性能IO之Reactor:https://www.cnblogs.com/doit8791/p/7461479.html
- 细说Reactor模式:https://blog.csdn.net/u010168160/article/details/53019039
Reactor模式是什么:https://blog.csdn.net/u013219087/article/details/81229873
Reactor模式详解:http://www.blogjava.net/DLevin/archive/2015/09/02/427045.html
- Reactor(反应器)模式初探:https://blog.csdn.net/pistolove/article/details/53152708
- Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events

